Source des données
J’ai récupéré les données du site wri.org, qui est l’organisme qui collecte et produit les statistiques pour le climat.
Ils ont un outils pas mal foutu du tout, par contre il y a des comparaisons qu’on ne peut pas faire , comme comparer des groupes de pays .
J’ai donc choisi, les gaz à effet de serre, sur plusieurs groupes de pays différents.
Représentativité et géopolitique
Attention: Certains pays sont membres de plusieurs groupes.
Total période 1970 à 2019
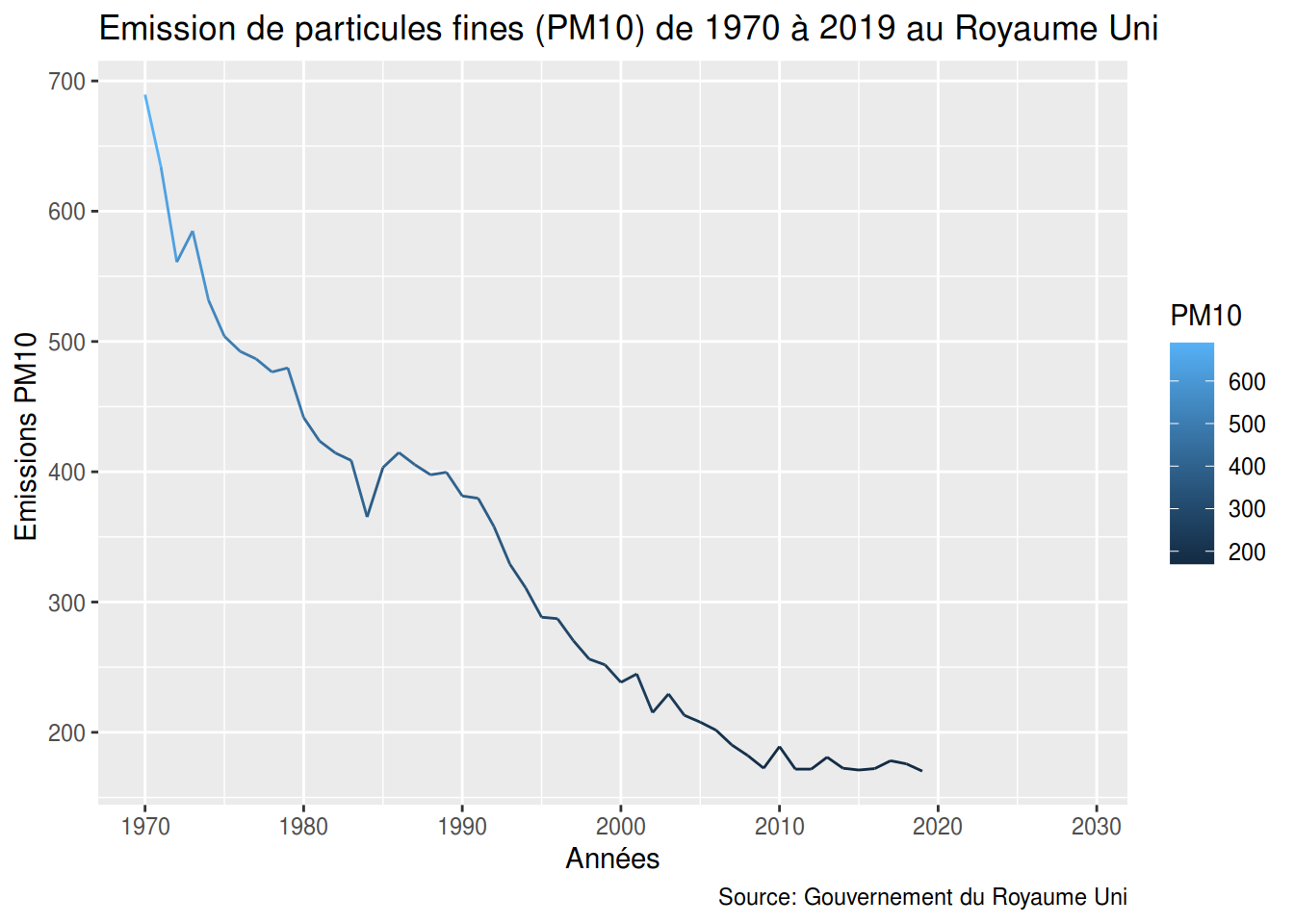
PM10
library(readr)
PM10_PM25_Time_Series <- read_csv("PM10_PM25_Time_Series.csv")
## Rows: 60 Columns: 4
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## dbl (4): year, pm10, pm25, ceiling2020
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
library(ggplot2)
ggplot(PM10_PM25_Time_Series, aes(year,pm10)) +
geom_line(aes(color=pm10)) +
labs(title = "Emission de particules fines (PM10) de 1970 à 2019 au Royaume Uni",
caption = "Source: Gouvernement du Royaume Uni",
x = "Années",
y = "Emissions PM10 ",
colour = "PM10",
)
## Warning: Removed 10 rows containing missing values or values outside the scale range
## (`geom_line()`).
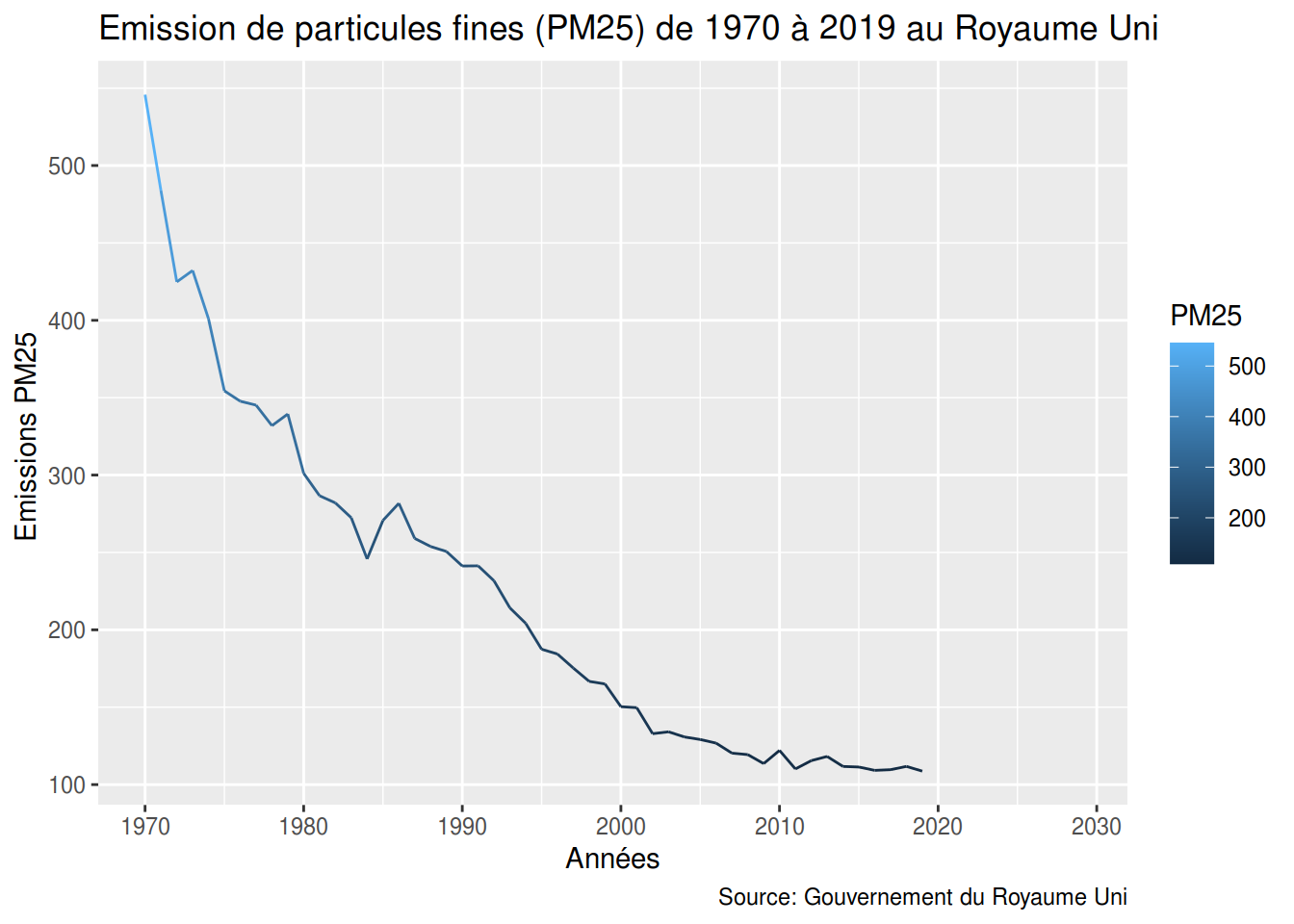
PM25
library(readr)
PM10_PM25_Time_Series <- read_csv("PM10_PM25_Time_Series.csv")
## Rows: 60 Columns: 4
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## dbl (4): year, pm10, pm25, ceiling2020
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
library(ggplot2)
ggplot(PM10_PM25_Time_Series, aes(year,pm25)) +
geom_line(aes(color=pm25)) +
labs(title = "Emission de particules fines (PM25) de 1970 à 2019 au Royaume Uni",
caption = "Source: Gouvernement du Royaume Uni",
x = "Années",
y = "Emissions PM25 ",
colour = "PM25",
)
## Warning: Removed 10 rows containing missing values or values outside the scale range
## (`geom_line()`).
1990, 2005, 2018, 2019
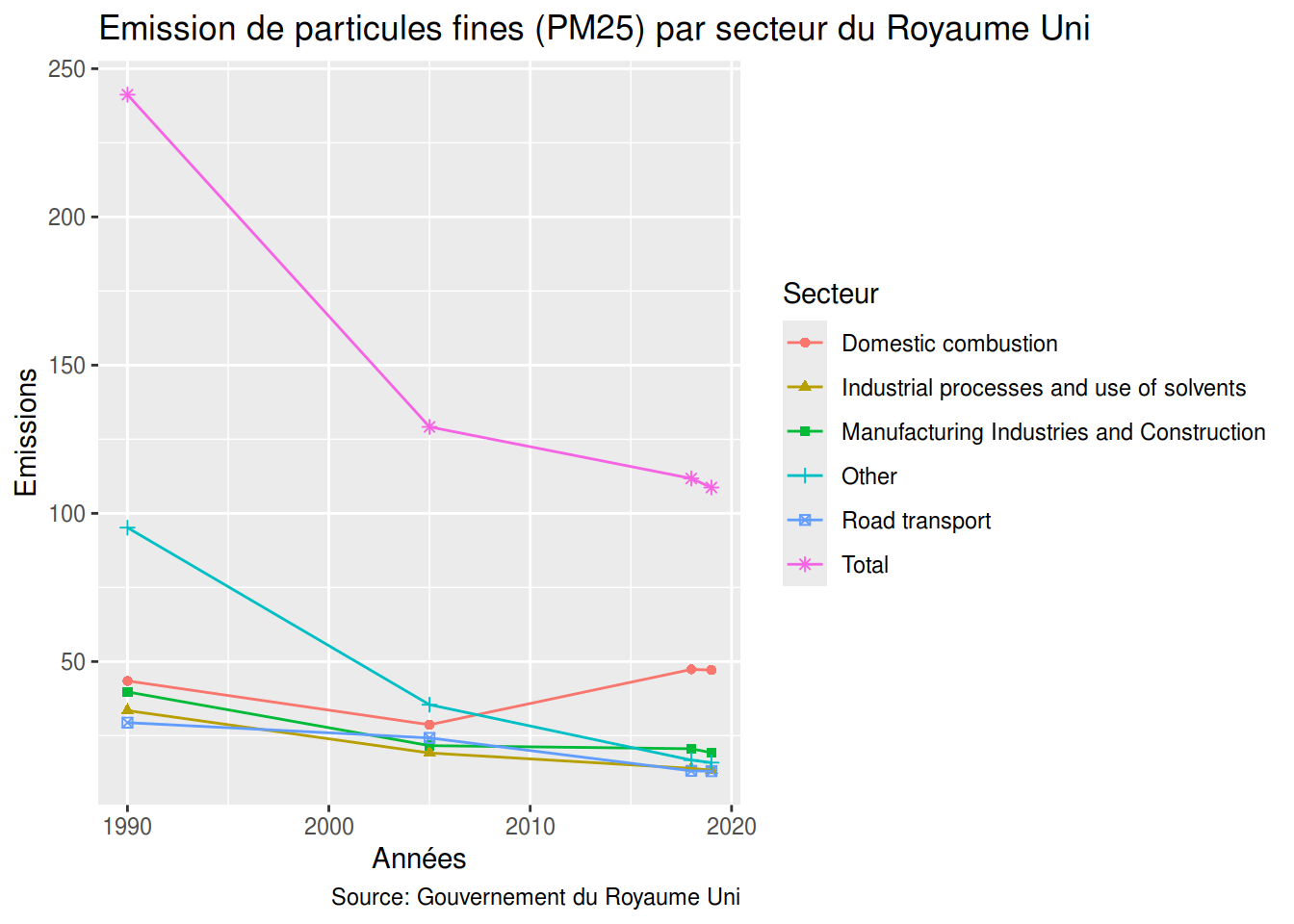
PM25
library(readr)
uk_PM2_5_sector <- read_csv("uk_PM2_5_sector.csv")
## Rows: 24 Columns: 4
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (2): Sector, ver
## dbl (2): Year, Emissions
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
library(ggplot2)
ggplot(uk_PM2_5_sector, aes(Year,Emissions)) +
geom_point(aes(color=Sector, shape=Sector)) +
geom_line(aes(color=Sector)) +
labs(title = "Emission de particules fines (PM25) par secteur du Royaume Uni",
caption = "Source: Gouvernement du Royaume Uni",
x = "Années",
y = "Emissions",
colour = "Secteur",
shape = "Secteur"
)
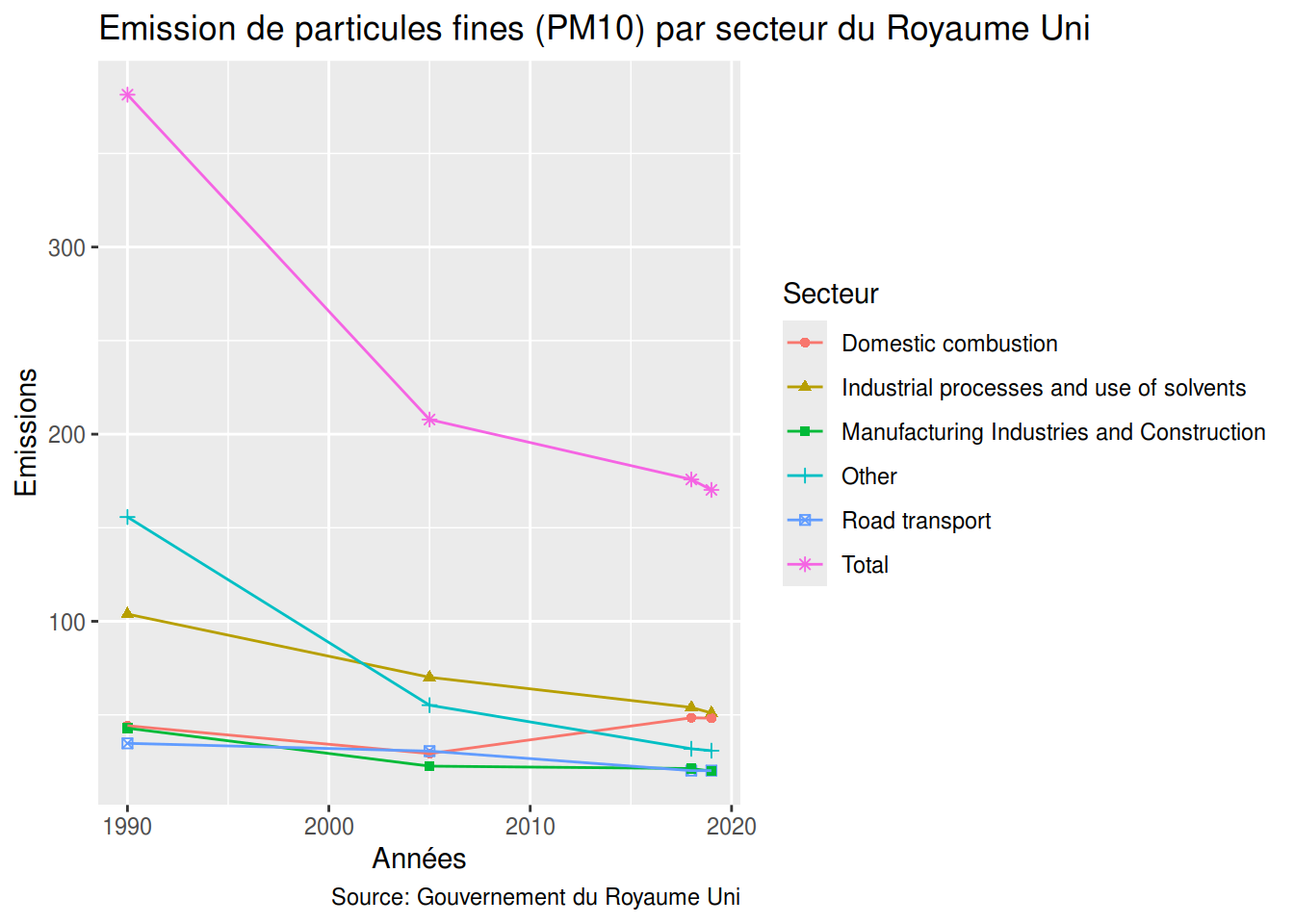
PM10
library(readr)
uk_PM10_sector <- read_csv("uk_PM10_sector.csv")
## Rows: 24 Columns: 4
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (2): Sector, ver
## dbl (2): Year, Emissions
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
library(ggplot2)
ggplot(uk_PM10_sector, aes(Year,Emissions)) +
geom_point(aes(color=Sector, shape=Sector)) +
geom_line(aes(color=Sector)) +
labs(title = "Emission de particules fines (PM10) par secteur du Royaume Uni",
caption = "Source: Gouvernement du Royaume Uni",
x = "Années",
y = "Emissions",
colour = "Secteur",
shape = "Secteur"
)
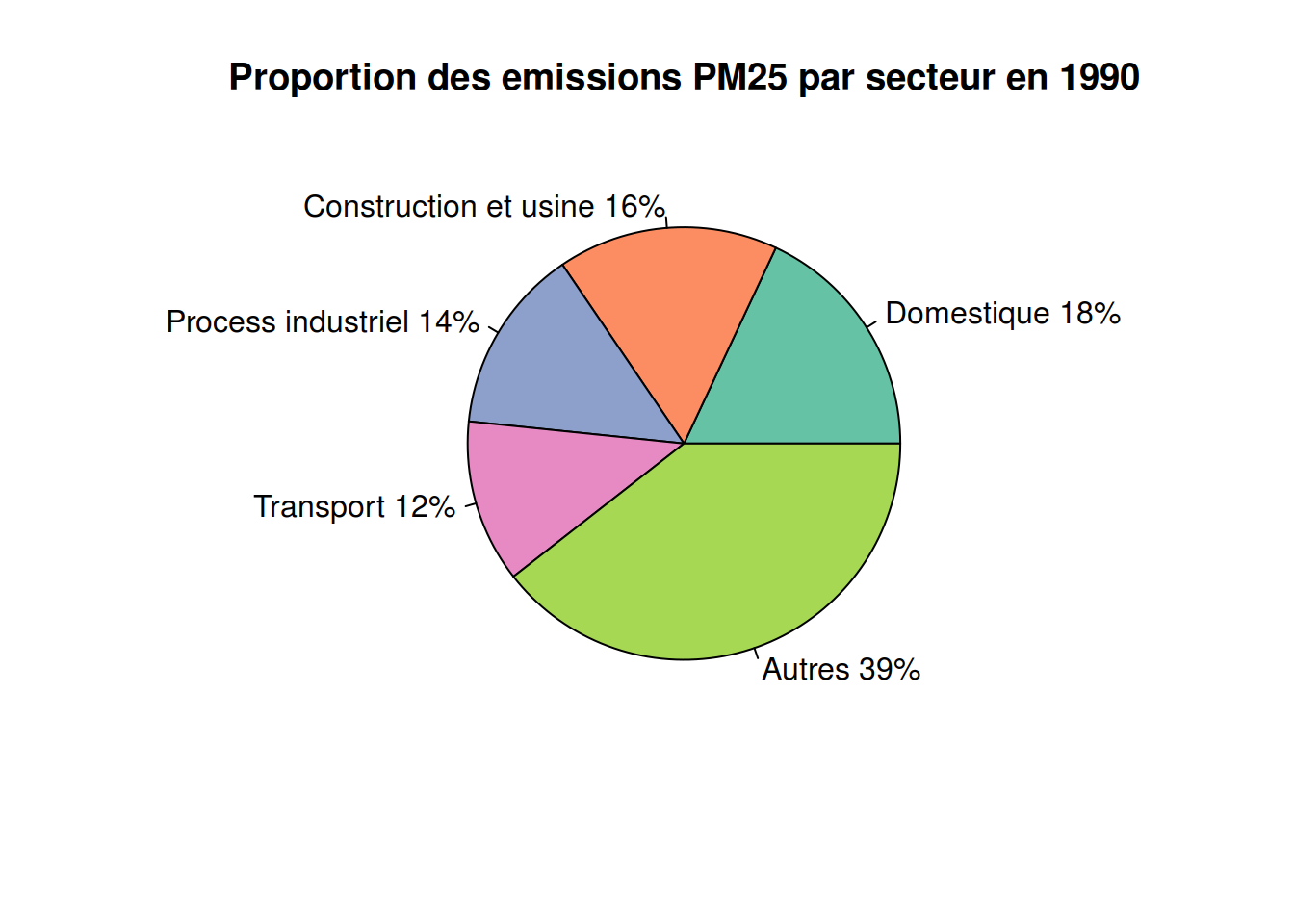
Proportion des emissions PM25 par secteur en 1990
library(RColorBrewer)
count <- c(43.46717718,39.75334,33.4542753,29.3908903,95.17064)
lbls <- c("Domestique","Construction et usine","Process industriel", "Transport","Autres")
color <- brewer.pal(length(count), "Set2")
pct <- round(count/sum(count)*100)
lbls <- paste(lbls,pct)
lbls <- paste(lbls,"%",sep = "" )
pie(count, labels = lbls, col = color, main = "Proportion des emissions PM25 par secteur en 1990")
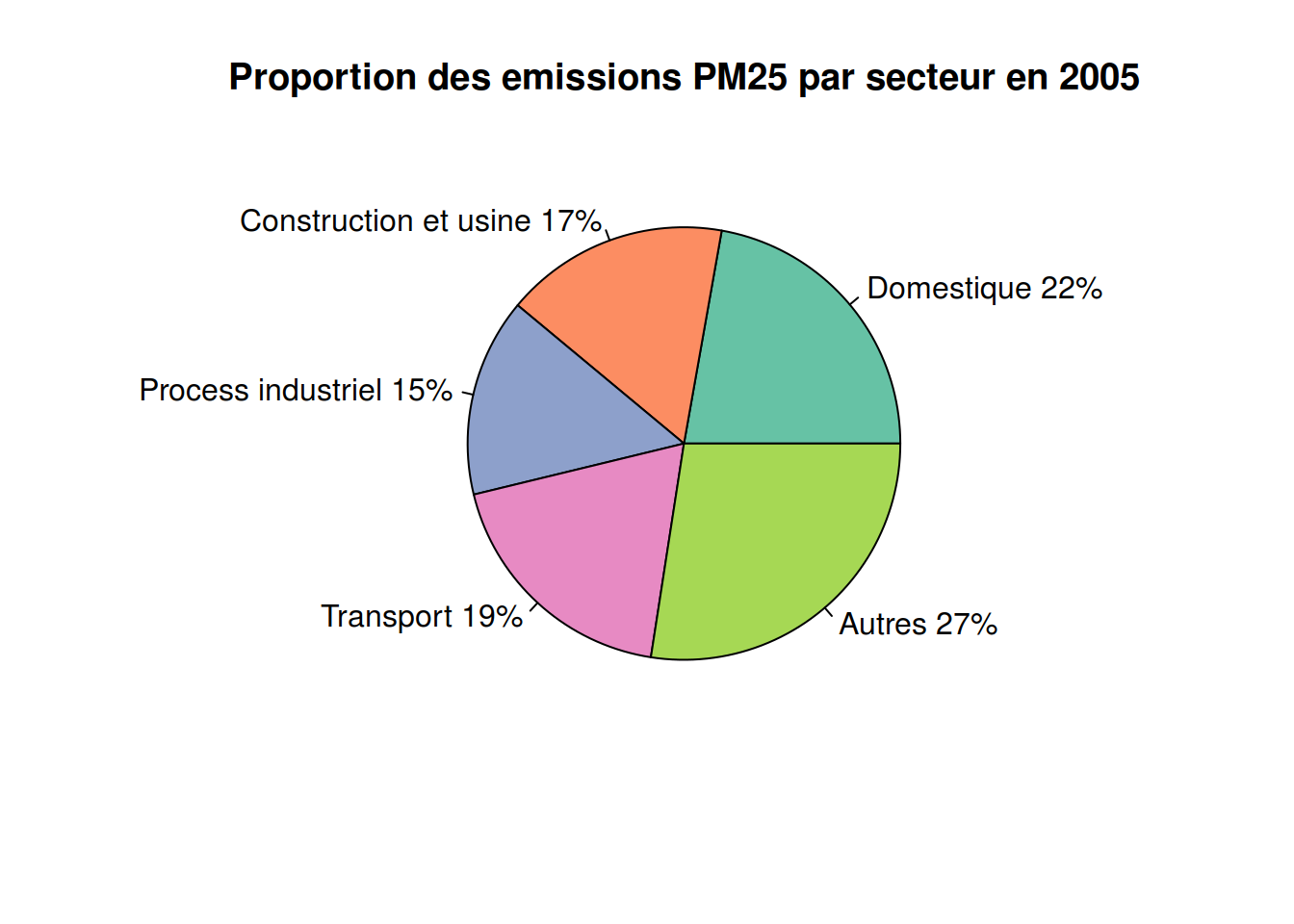
Proportion des emissions PM25 par secteur en 2005
library(RColorBrewer)
count <- c(28.68231526,21.63637793,19.15784332,24.23367353,35.4467)
lbls <- c("Domestique","Construction et usine","Process industriel", "Transport","Autres")
color <- brewer.pal(length(count), "Set2")
pct <- round(count/sum(count)*100)
lbls <- paste(lbls,pct)
lbls <- paste(lbls,"%",sep = "" )
pie(count, labels = lbls, col = color, main = "Proportion des emissions PM25 par secteur en 2005")
Proportion des emissions PM25 par secteur en 2018
library(RColorBrewer)
count <- c(47.35432128,20.5864062,13.94194731,13.12861116,16.75408)
lbls <- c("Domestique","Construction et usine","Process industriel", "Transport","Autres")
color <- brewer.pal(length(count), "Set2")
pct <- round(count/sum(count)*100)
lbls <- paste(lbls,pct)
lbls <- paste(lbls,"%",sep = "" )
pie(count, labels = lbls, col = color, main = "Proportion des emissions PM25 par secteur en 2018")
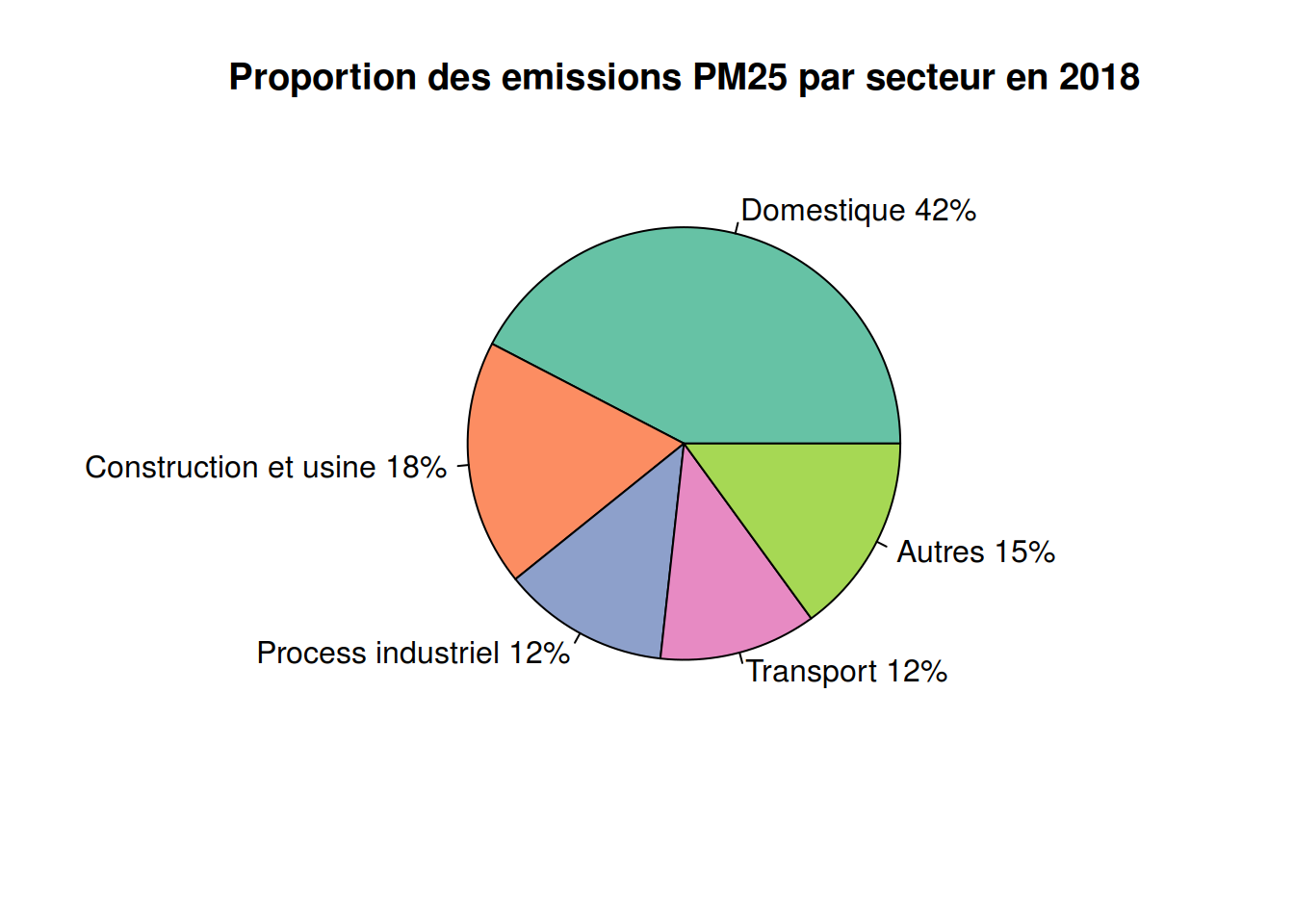
Proportion des emissions PM25 par secteur en 2019
library(RColorBrewer)
count <- c(47.13659663,19.25912284,13.37445948,13.03611225,15.90479)
lbls <- c("Domestique","Construction et usine","Process industriel", "Transport","Autres")
color <- brewer.pal(length(count), "Set2")
pct <- round(count/sum(count)*100)
lbls <- paste(lbls,pct)
lbls <- paste(lbls,"%",sep = "" )
pie(count, labels = lbls, col = color, main = "Proportion des emissions PM25 par secteur en 2019")
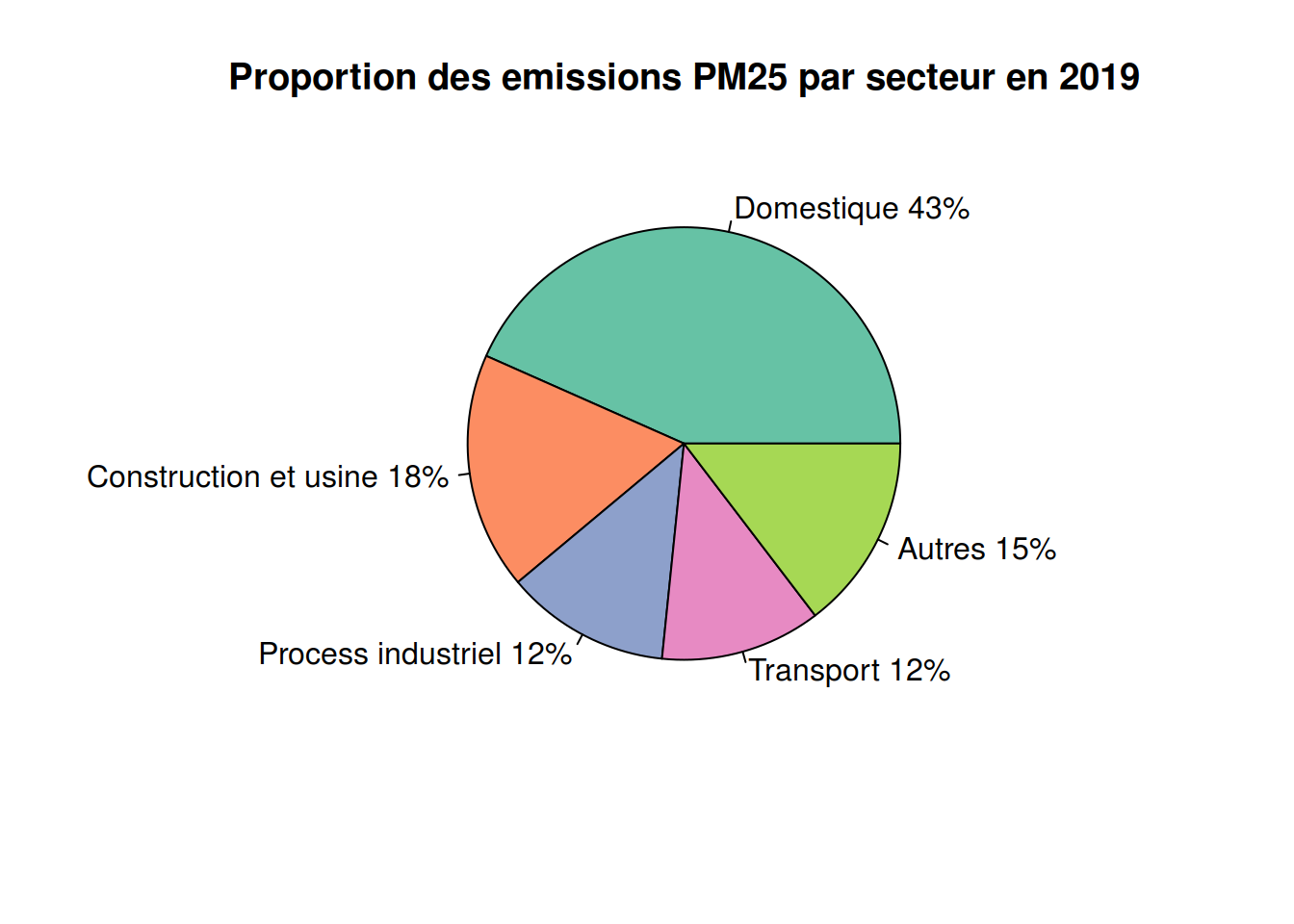
Source des données disponible sur gov.uk
Il existe de nombreux thèmes fourni par le package ggtheme inspirés de journaux, de société de la tech, d’autres logiciels ou encore d’un model de document connu par ceux qui éditent en TeX : tufte . (super classe les documents tufte).
Exemple ici
D’une manière générale , ces thèmes sont fait pour être utilisé tel quel . Pensez : le fond et la forme.
Ces thèmes vous fournissent la forme et vous ne vous occupez que du fond de votre sujet.
Dans le jeu de données iris , nous avions vu qu’il y avait 150 observations , avec un facteur catégorisant qui est l’espèce , au nombre de 3 :
- setosa
- versicolor
- virginica
Nous allons afficher la longueur et la largeur des sépales :
ggplot(data=iris, aes(x = Sepal.Length, y = Sepal.Width )) +
Appliquer un jeu de couleurs et de formes en fonction de ce facteur .
geom_point(aes(color=Species, shape=Species)) +
Mettre les labels en français. Nous avions vu que l’on pouvait definir les labels avec un bloc labs.
Testons le mode sombre
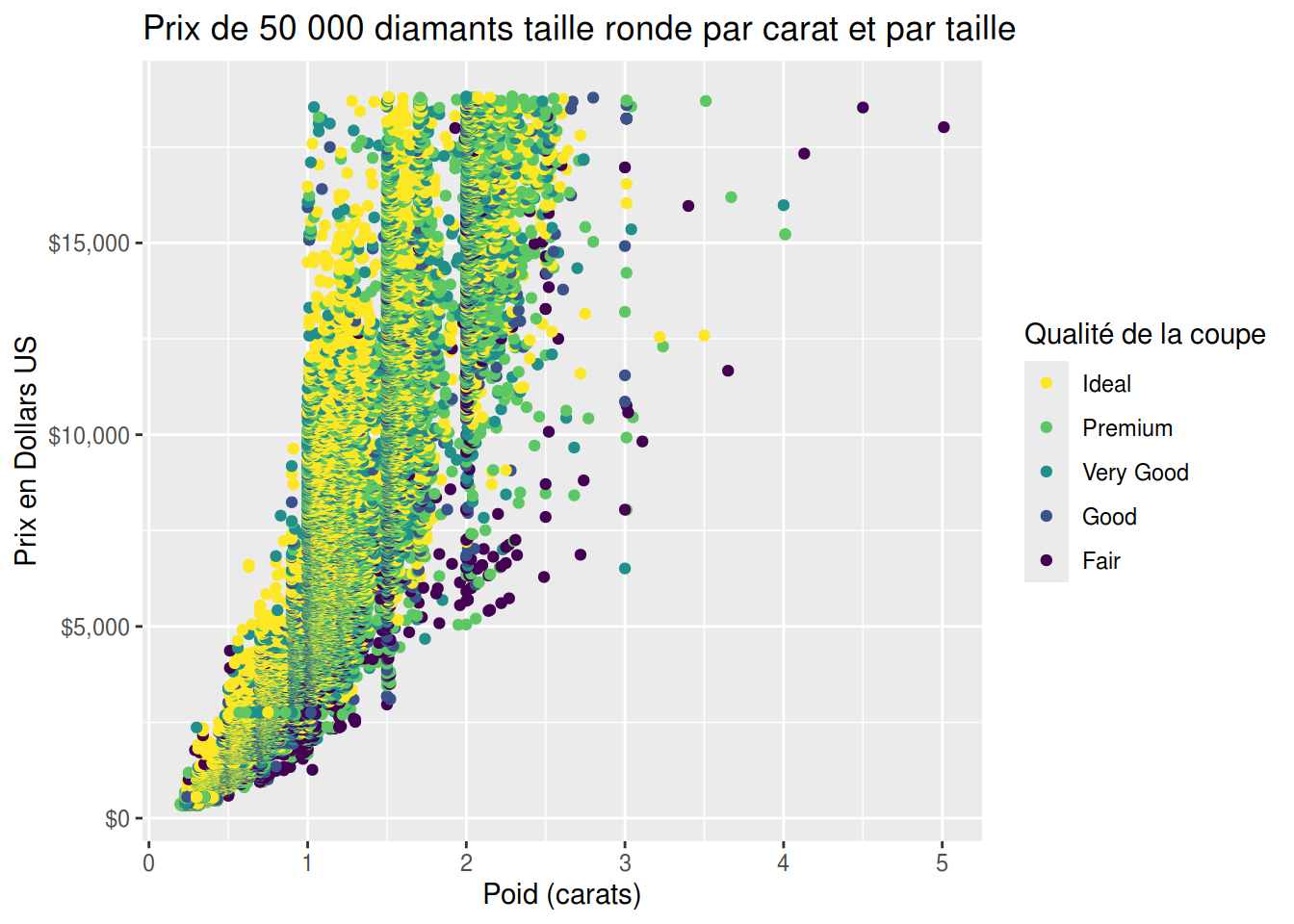
Prenons le jeu de données diamonds , et classons les diamants par prix (en dollars) et poids (carat) en fonction de la coupe .
Dés le début du code , on créé un *objet : p .
Cet objet ce créé simplement comme ceci p <- , qui nous permettra de contenir la définition de notre graphique .
library(ggplot2)
p <- ggplot(diamonds) +
geom_point(aes(carat, price, color = cut)) +
scale_y_continuous(label = scales::dollar) +
guides(color = guide_legend(reverse = TRUE)) +
labs(title = "Prix de 50 000 diamants taille ronde par carat et par taille",
x = "Poid (carats)",
y = "Prix en Dollars US",
color = "Qualité de la coupe")
p + theme_gray()
Librairie ggdark
Appliquons un theme sombre , c’est vraiment sympa.
Un peu de couleur
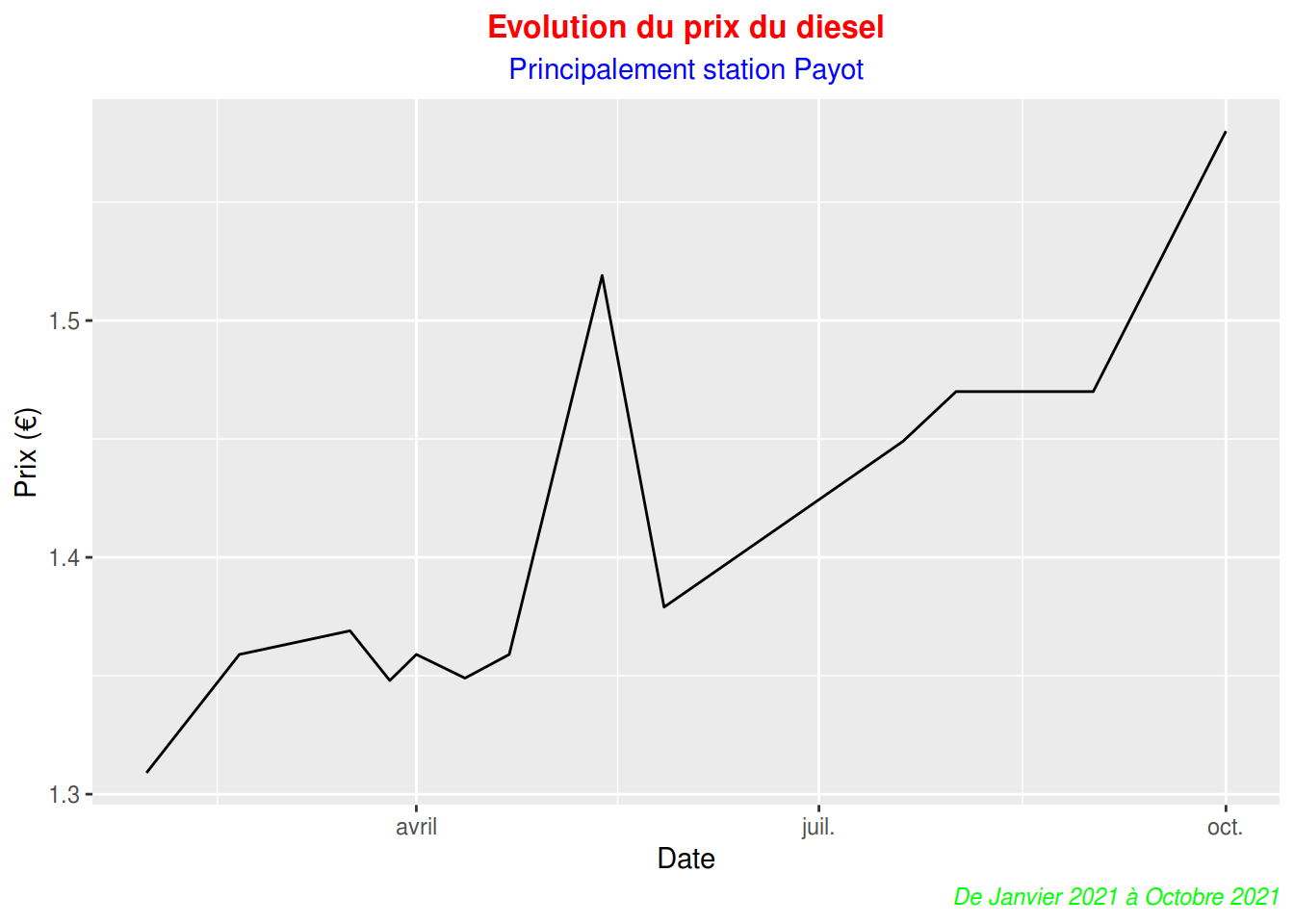
Ajoutons un peu de couleurs au graphique diesel:
library(ggplot2)
library(readr)
diesel <- read_delim("diesel.csv", delim = ";",
escape_double = FALSE, col_types = cols(Date = col_date(format = "%d/%m/%Y"),
Prix = col_number()), locale = locale(date_names = "fr",
decimal_mark = ","), trim_ws = TRUE)
# View(diesel)
ggplot(diesel, aes(Date,Prix)) +
geom_line()+
labs(title = "Evolution du prix du diesel",
subtitle = "Principalement station Payot",
caption = "De Janvier 2021 à Octobre 2021",
y = "Prix (€)") +
theme(
plot.title = element_text(color = "red", size = 12,
face = "bold", hjust = 0.5),
plot.subtitle = element_text(color = "blue", hjust = 0.5),
plot.caption = element_text(color = "green", face = "italic")
)
R connait une liste de 657 couleurs, c’est pas mal.
iris, mtcars, diamonds
R fourni des jeu de données , très pratique car contenant l’ensemble des caractéristiques permettant d’exploiter les fonctions de R.
iris contient un jeu de données de 50 plantes de 3 espèces d’iris différentes.
En botanique la taxonomie en fait de cette manière: genre, espèce, nom commun, famille.
C’est espèces sont:
- setosa
- virginica
- versicolor
Et pour chacune de ces espèces, les observation sont:
- la largeur et la longueur des sépales
- la largeur et la longueur des pétales
Exemple simple sans data
On crée un simple graphique en barre barplot, en leur attribuant une valeur arbitraire (c(3, 7)), puis on applique une couleur (moche) de manière tout aussi arbitraire , col = c("darkblue", "red").
Ajoutons un titre
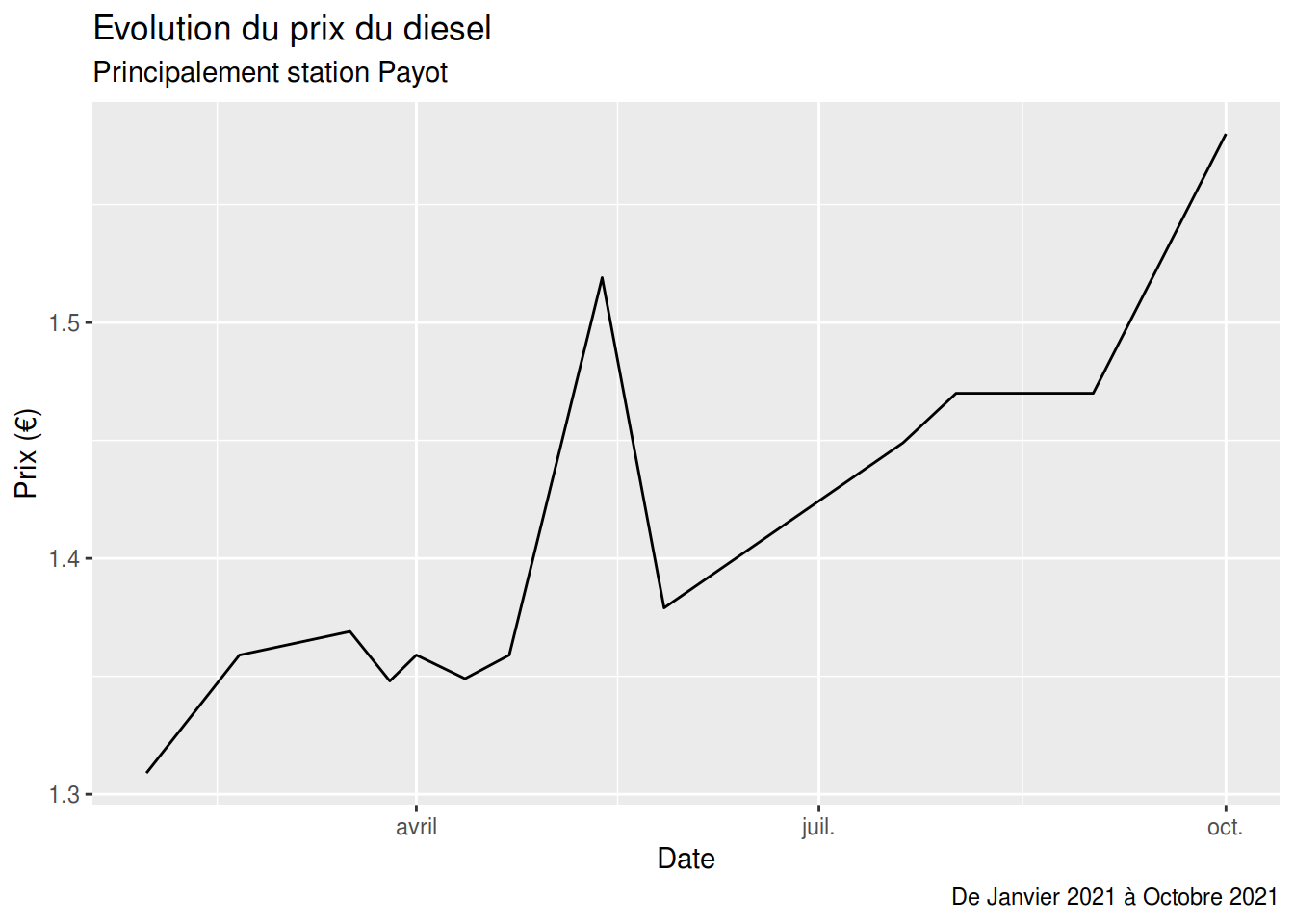
Un titre s’ajoute simplement avec labs pour label, qui dispose de plusieurs options, le code et le graphique sont suffisamment explicite pour ne pas détailler.
Nous pouvons donc ajouter:
- un titre
- un sous-titre
- une légende
C’est ce que je nomme le fond que je distingue de la forme.
library(readr)
diesel <- read_delim("diesel.csv", delim = ";",
escape_double = FALSE, col_types = cols(Date = col_date(format = "%d/%m/%Y"),
Prix = col_number()), locale = locale(date_names = "fr",
decimal_mark = ","), trim_ws = TRUE)
library(ggplot2)
ggplot(diesel, aes(Date,Prix)) +
geom_line()+
labs(title = "Evolution du prix du diesel",
subtitle = "Principalement station Payot",
caption = "De Janvier 2021 à Octobre 2021",
y = "Prix (€)")
J’aborderais ce principe dans un article sur le markdown , mais d’une manière générale les documents textes un peu élaboré fonctionnent sur le même principe . C’est la mise en page.
R Markdown
This is an R Markdown document. Markdown is a simple formatting syntax for authoring HTML, PDF, and MS Word documents. For more details on using R Markdown see http://rmarkdown.rstudio.com.
You can embed an R code chunk like this:
summary(cars)
## speed dist
## Min. : 4.0 Min. : 2.00
## 1st Qu.:12.0 1st Qu.: 26.00
## Median :15.0 Median : 36.00
## Mean :15.4 Mean : 42.98
## 3rd Qu.:19.0 3rd Qu.: 56.00
## Max. :25.0 Max. :120.00
fit <- lm(dist ~ speed, data = cars)
fit
##
## Call:
## lm(formula = dist ~ speed, data = cars)
##
## Coefficients:
## (Intercept) speed
## -17.579 3.932
Including Plots
You can also embed plots. See Figure 1 for example: